
基于 QChatGPT 项目的插件能力 实现的自动答疑机器人
原理
将需要答疑的领域的相关问题及其解答内容分割成多个文档,从 OpenAI Embeddings 接口 获取文档的向量值,储存到向量数据库(本例中使用 搭配了向量计算插件的 PostgreSQL 数据库)中,在用户问题达到时,计算用户问题的向量值,从数据库中查找出最相近的几个文档,输入给 OpenAI 的 GPT 模型生成自然语言回复。
实现
- 负责沟通 QQ 等消息平台:https://github.com/RockChinQ/QChatGPT
- QChatGPT 插件,用户接收问题并从 llm-embed-qa 接口获取回复:https://github.com/RockChinQ/AnsweringPlugin
- 用于处理文档向量值并组织数据库,开放接口供插件调用:https://github.com/RockChinQ/llm-embed-qa
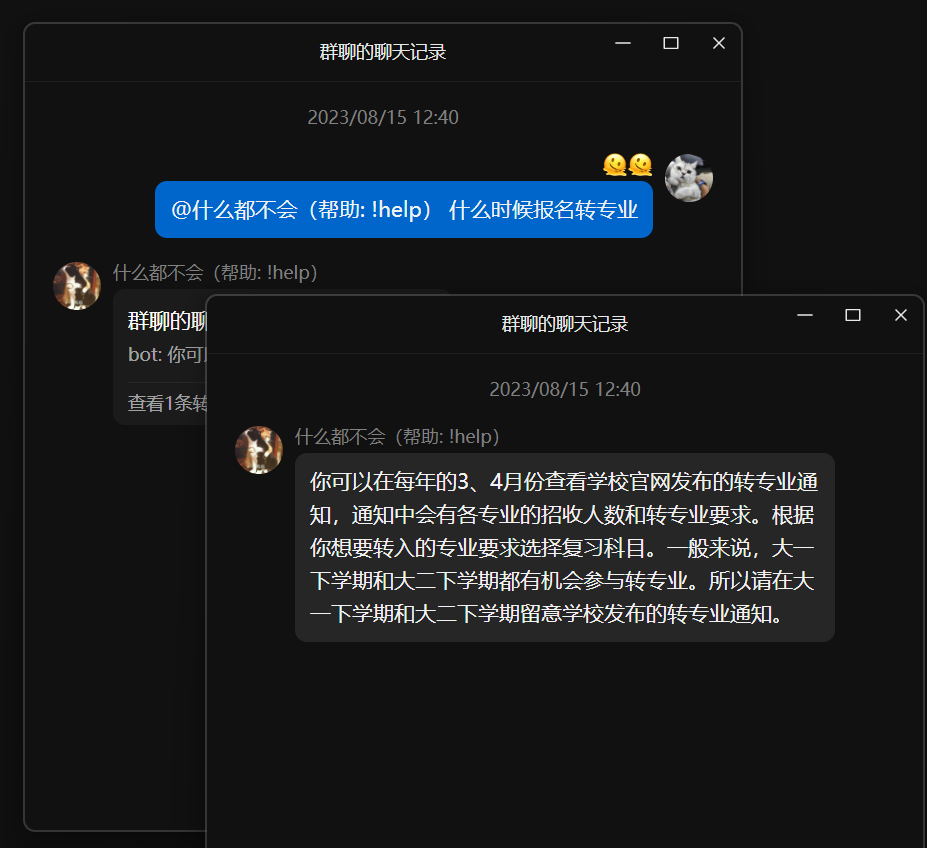
按照 QChatGPT 文档配置好主程序,按照 llm-embed-qa 的文档进行配置,之后按照插件文档进行安装,配置 llm-embed-qa 的地址后即可向机器人提问相关内容。
- 示例:天津理工大学转专业相关资料库:https://github.com/RockChinQ/TJUT-ChangeMajor

局限性和改进
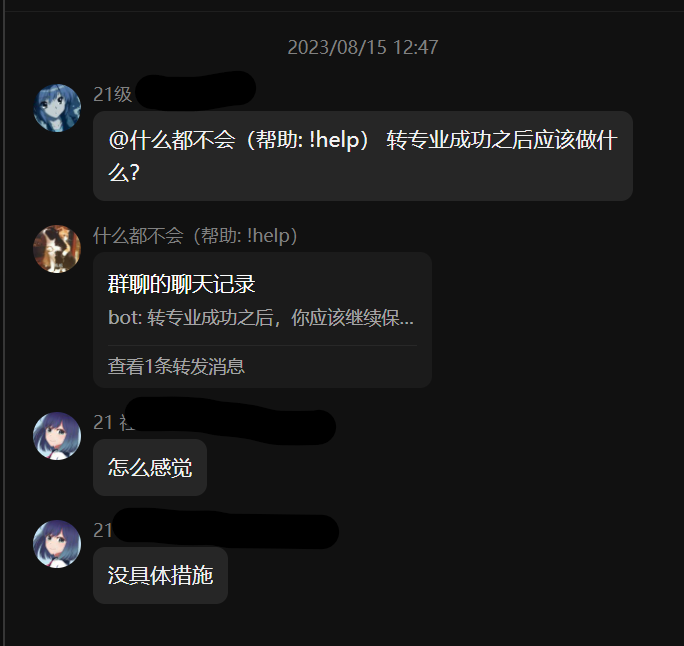
- 目前将整个文档(包含问题和示例回复)混到一起计算向量值,会导致当用户的问题与文档中的问题相符,但与回复相差甚远时,此文档不会被匹配到。应该为仅计算问题的向量值并存进数据库。
- 目前均为人工分割大段语料成数个小文档,可以改为尝试使用 OpenAI GPT 进行自动分割。
发表回复