
代码开源在:https://gitee.com/RockChin/SampleCodes/tree/main/2023/11/NewsPageCrawler
直接测试
安装依赖:
pip install pandas openpyxl requests fake-useragent beautifulsoup4将上方的链接中的 crawler.py 的内容保存到本地文件,执行:
python crawler.py程序将爬取 https://news.tjut.edu.cn/yw1.htm 上每条新闻的 标题、发布日期、每张图片链接 并保存到 news.xlsx
实现原理
首先确定目标网站 https://news.tjut.edu.cn/yw1.htm , 到页面上右键“检查元素”
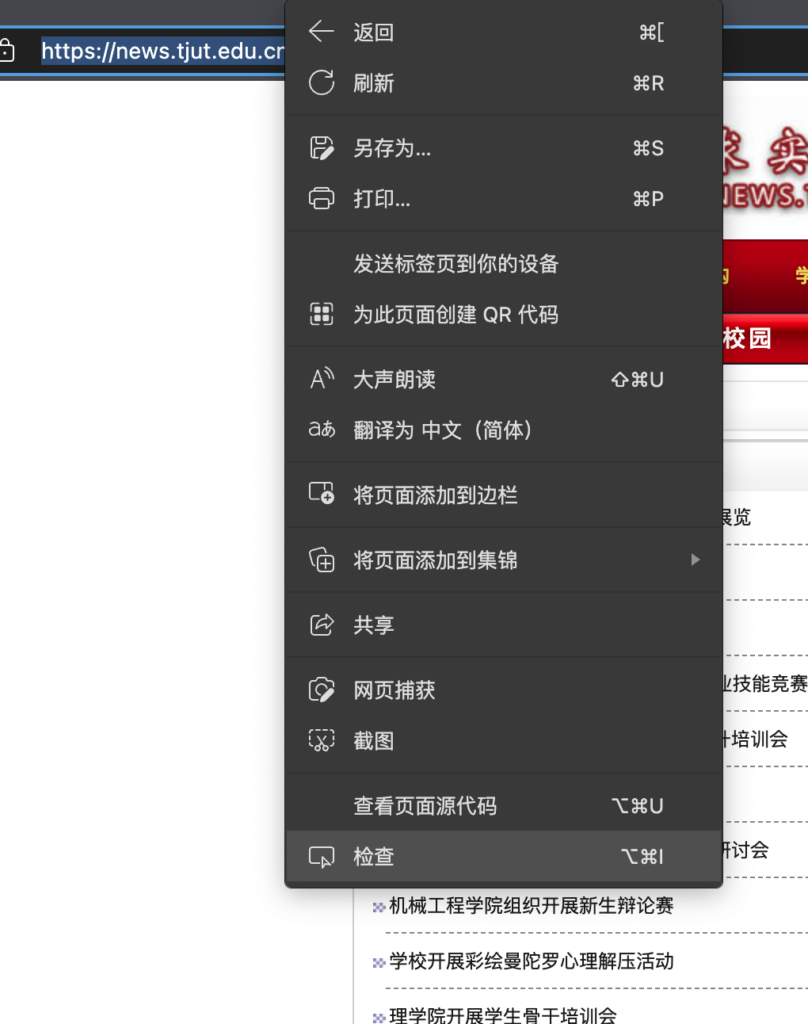
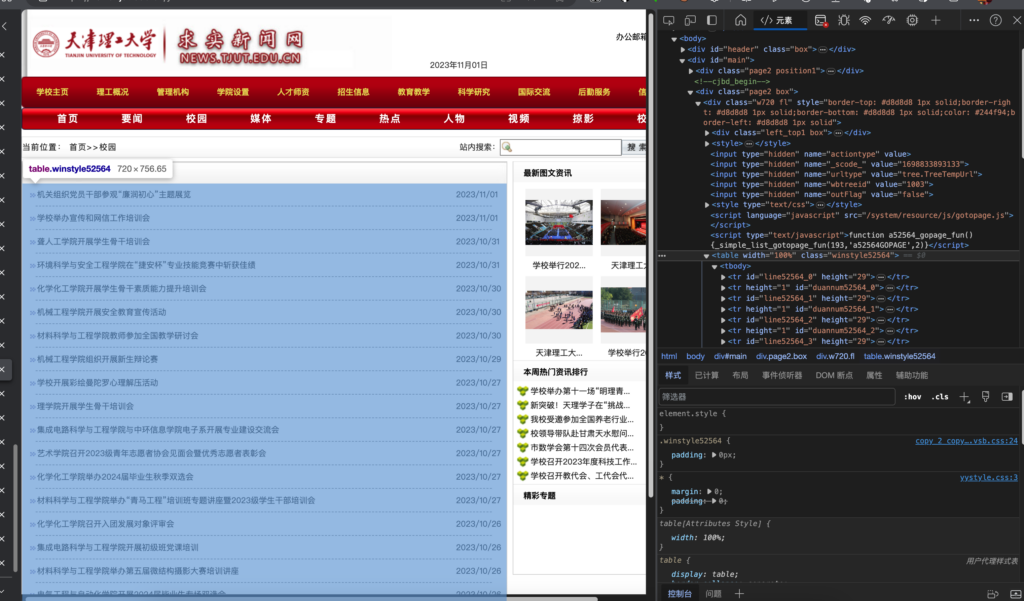
挨个展开,选中包含了新闻标题的表格元素:
右键 “复制selector”
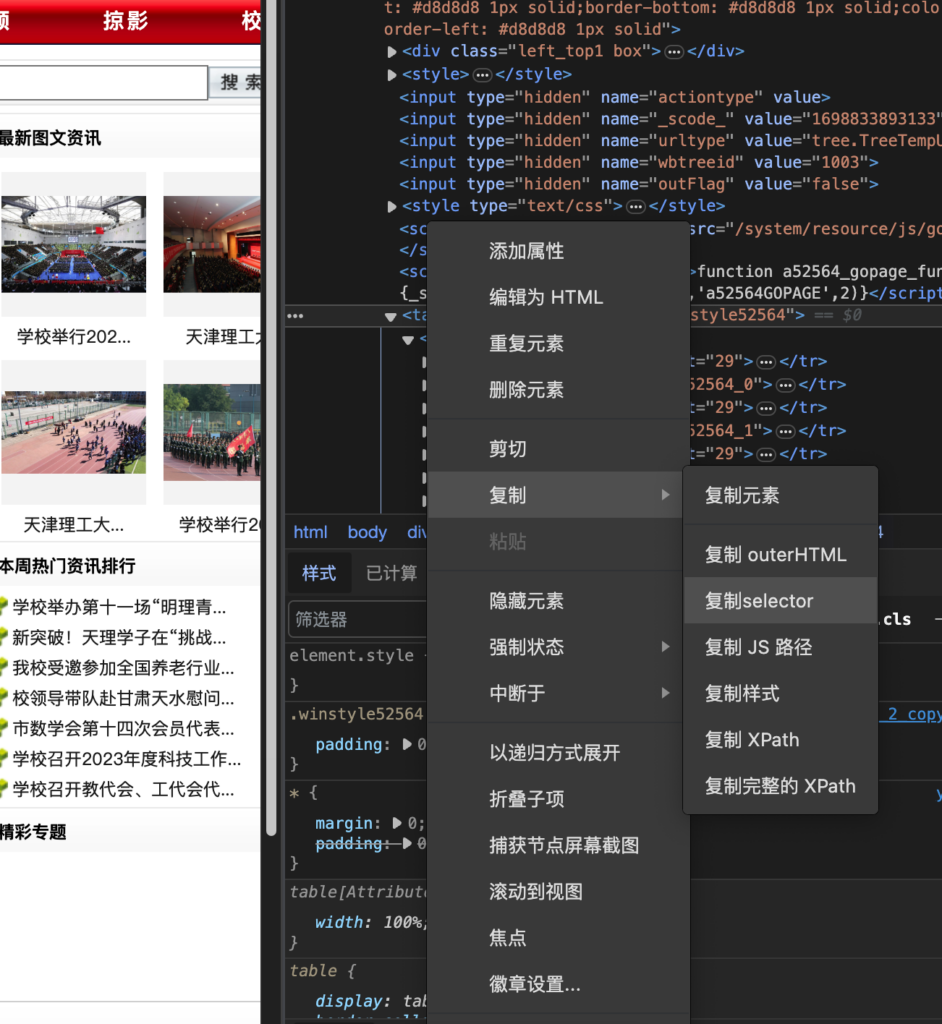
就是这个:main > div.page2.box > div.w720.fl > table
现在开始写代码:
# 引入re模块 正则表达式提取时间
import re
# 引入requests用于发送http请求 下载网页源码
import requests
# 引入fake_useragent用于生成随机User-Agent 以实现反反爬
from fake_useragent import UserAgent
# 引入BeautifulSoup用于解析网页源码
from bs4 import BeautifulSoup
# 引入pandas用于处理并保存数据到Excel
import pandas as pd
# 此爬虫爬取天津理工大学的某个新闻板块内容:https://news.tjut.edu.cn/yw1.htm
# 并逐一爬取每个新闻详情页中的标题、时间、配图
# 最后将数据保存到Excel中
main_page_url = 'https://news.tjut.edu.cn/yw1.htm'
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding":"gzip, deflate, br",
"Accept-Language":"zh-CN,zh;q=0.9",
"User-Agent": UserAgent().random
}
# 发送http请求,获取网页源码
response = requests.get(main_page_url, headers=headers, timeout=10)
response.encoding = "utf-8"
# 解析网页源码
main_page_soup = BeautifulSoup(response.text, 'html.parser')这里直接使用 requests 来发送请求,并且带上了一些请求头,这些不重要,只有一些反爬策略做得很严格的网站才会去校验这种东西。
然后拿到了网页的源码(HTML),最后放到BeautifulSoup4里进行解析。
接下来就按照前面获得的元素的路径来获取元素对象:
# 获取新闻列表元素
main_page_news_list = main_page_soup.select_one("#main > div.page2.box > div.w720.fl > table")
# 提取所有tr元素
trs = main_page_news_list.select("tr")在网页中继续展开刚刚的table元素,也可以看到里面有很多tr,tr下包含了新闻的标题和详细页链接。
而其中只有id为line开头的才是真正的新闻链接,其他的是分割线:
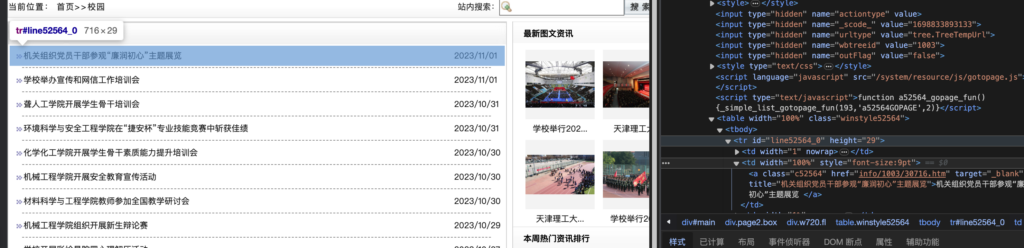
所以写个筛选:
# 删除分割线, 只保留id为line开头的tr元素, 这些才是新闻标题
filtered_trs = []
for tr in trs:
if tr is not None and tr.get("id") is not None and tr.get("id").startswith("line"):
filtered_trs.append(tr)
print("新闻条数:", len(filtered_trs))接下来就可以遍历每个新闻详细页然后获取所需信息(标题、时间、配图链接们)
# 爬取每个新闻详情页的标题、时间、配图
news_list = []
"""
数据结构:
[
{
"title": "xxx",
"time": "xxx",
"images: [
"xxx",
"xxx"
]
}
]
"""
root_url = "https://news.tjut.edu.cn/"
for tr in filtered_trs:
# 这里就是处理每个新闻详细页,下方讲解可以观察到,新闻列表中tr的第二个td元素内为有效的链接元素:
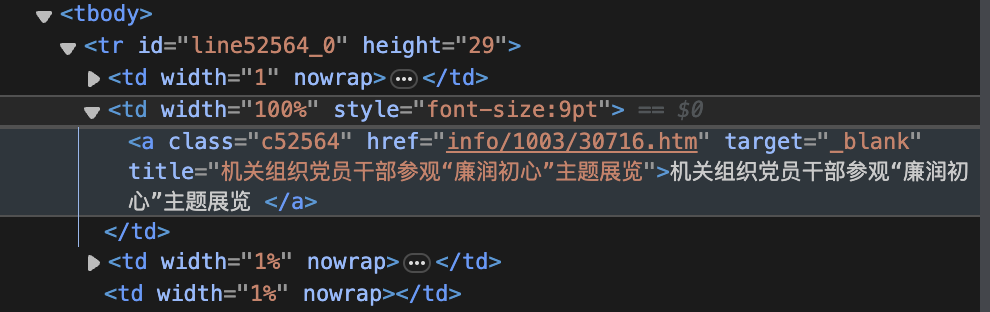
取出来,而新闻详情页链接就是https://news.tjut.edu.cn/拼接上这个a元素的href值,用requests下载页面源代码:
# 获取tr内所有td元素
tds = tr.select("td")
if tds is None or len(tds) < 4:
continue
# 获取新闻详情页url
detail_url = root_url + tds[1].select_one("a").get("href")
# print(detail_url)
# 发送http请求,获取网页源码
response = requests.get(detail_url, headers=headers, timeout=10)
response.encoding = "utf-8"
# 解析网页源码
detail_page_soup = BeautifulSoup(response.text, 'html.parser')接下来就依葫芦画瓢了,前往新闻详情页,找到包含标题、时间的元素,这里使用find函数:查找class为指定值的div元素,因为整个html中只有这一个div元素具有这个class名称,所以可以直接找到需要的:
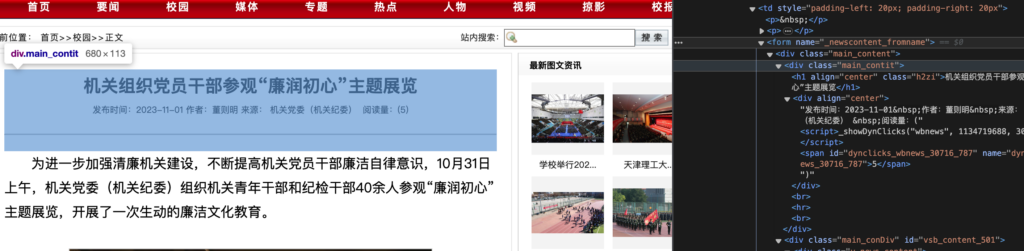
# 获取新闻标题
# 元素后面.text即可获取其中的纯文本
title = detail_page_soup.find("div", class_="main_contit").select_one("h1").text
# 获取新闻时间
sub_title = detail_page_soup.find("div", class_="main_contit").select_one("div").text
time_str = re.findall(r"\d{4}-\d{2}-\d{2}", sub_title)[0]新闻时间,我们使用了一个正则表达式来提取,正则表达式教程可以看看:https://www.runoob.com/regexp/regexp-tutorial.html
新闻的所有配图,就在正文这个class=”main_conDiv”的元素中查找所有的img元素即可:
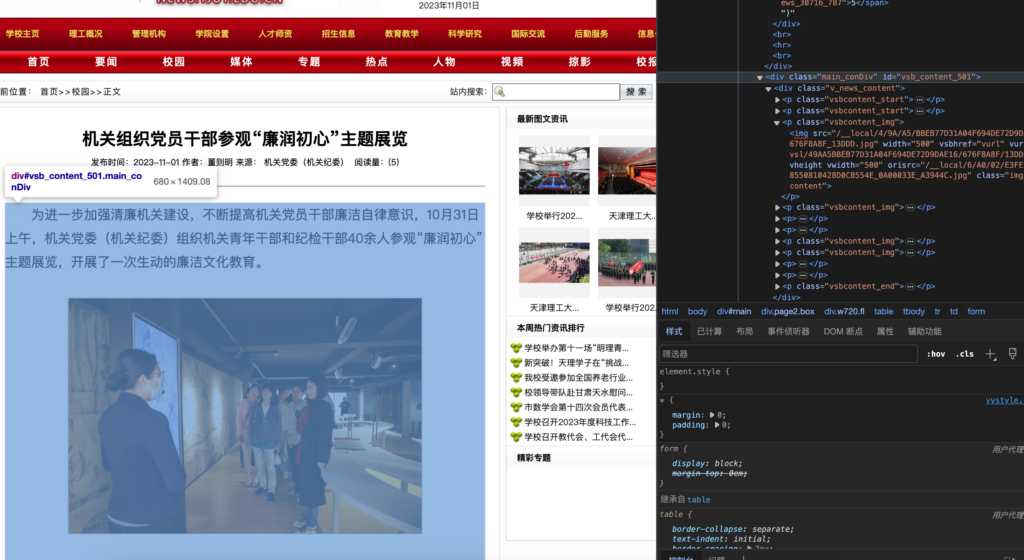
# 获取新闻配图
imgs_elements = detail_page_soup.find("div", class_="main_conDiv").select("img")
imgs = []
# 同样是https://news.tjut.edu.cn/拼接上图片的src属性就是图片的访问链接
for img_element in imgs_elements:
imgs.append(root_url+img_element.get("src"))存到news_list列表中:
news_list.append({
"title": title,
"time": time_str,
"images": imgs
})现在我们取得了所有新闻的标题、时间和配图列表,跳出循环了,下一步是保存到excel
直接使用pandas的导出到excel到功能,把每一个新闻都包装成一个DataFrame,拼接到整个DataFrame中,最后导出到news.xlsx
# 初始化pandas的DataFrame
df = pd.DataFrame(columns=['新闻标题', '发布日期'])
# 遍历每一条新闻数据
for new in news_list:
data = {
'新闻标题': [new['title']],
'发布日期': [new['time']]
}
# 插入每一个图片链接
for i in range(len(new['images'])):
data['图片链接{}'.format(i+1)] = [new['images'][i]]
# 将每一条新闻数据转换为DataFrame
df = pd.concat([df, pd.DataFrame(data)])
# 保存数据到Excel
df.to_excel('news.xlsx', index=False)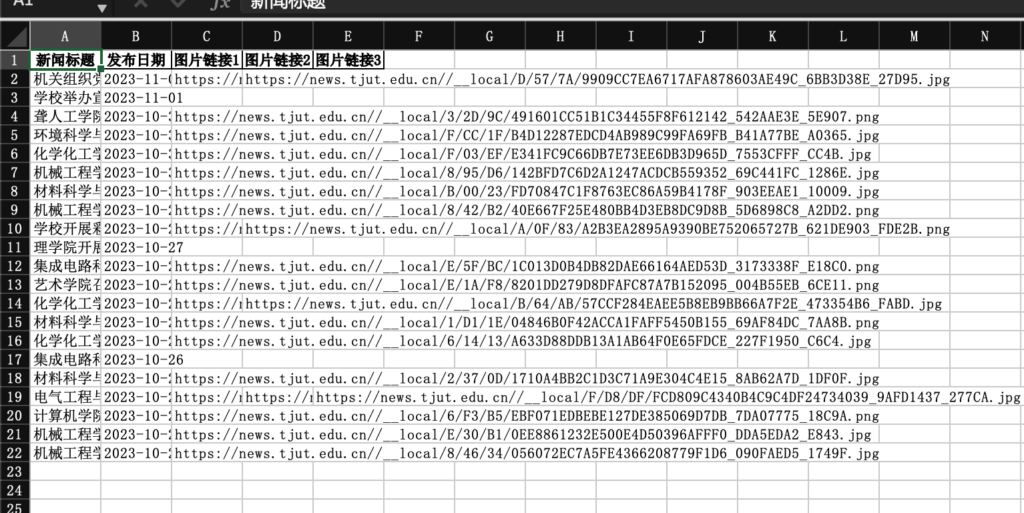
发表回复